

Julia Word Embedding with Dracula
According to Wikipedia “Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers”.
It is word vectors that make technologies such as speech recognition and machine translation possible. The algorithms to create them come from the likes of Google’s (Word2Vec), Facebook’s (FastText) and Stanford University’s (GloVe). For this notebook we will use a pre-trained embedding file built using GloVe.
The embedding file I used below is glove.6B.50d.txt. This file can be downloaded from GloVe and needs to be in the current working folder for this example.
The ideas explored below come from a brilliant GitHub Post Understanding word vectors … for, like, actual poets. By Allison Parrish. This was a Python notebook and I have basically re-written part of it in Julia. Very little credit goes to me!
Let’s begin by loading the packages we will need.
using Distances, Statistics
using MultivariateStats
using PyPlot
using WordTokenizers
using TextAnalysis
using DelimitedFiles
Load the Embeddings
There is a Julia package to load the embeddings with one or two lines of code called Embeddings.jl but I couldn’t get the package to install. I figured out the code to load the embeddings by delving into the repository.
function load_embeddings(embedding_file)
local LL, indexed_words, index
indexed_words = Vector{String}()
LL = Vector{Vector{Float32}}()
open(embedding_file) do f
index = 1
for line in eachline(f)
xs = split(line)
word = xs[1]
push!(indexed_words, word)
push!(LL, parse.(Float32, xs[2:end]))
index += 1
end
end
return reduce(hcat, LL), indexed_words
end
The function above takes the input of the embeddings filename and returns two arrays: -
-
embeddings – A Float32 Array, each row represents one word as an d dimensional vector
-
vocab – A string array of all the words
embeddings, vocab = load_embeddings("glove.6B.50d.txt")
vec_size, vocab_size = size(embeddings)
println("Loaded embeddings, each word is represented by a vector with $vec_size features. The vocab size is $vocab_size")
Loaded embeddings, each word is represented by a vector with 50 features. The vocab size is 400000
Lost? Don’t worry hang in there! Let’s see what in these arrays by way of some simple functions and examples.
Functions we’ll need
The function vec_idx returns the index position of a given word in the vocab. We can see that “cheese” is the 5796th word.
vec_idx(s) = findfirst(x -> x==s, vocab)
vec_idx("cheese")
5796
The function vec returns the word vector of the given word. Below is the vector for the word “cheese”.
function vec(s)
if vec_idx(s)!=nothing
embeddings[:, vec_idx(s)]
end
end
vec("cheese")
50-element Array{Float32,1}:
-0.053903
-0.30871
-1.3285
-0.43342
0.31779
1.5224
-0.6965
-0.037086
-0.83784
0.074107
-0.30532
-0.1783
1.2337
⋮
1.9502
-0.53274
1.1359
0.20027
0.02245
-0.39379
1.0609
1.585
0.17889
0.43556
0.68161
0.066202
It’s pretty difficult to imagine words in a 50 dimensional space so let’s have a think about how some word vectors might look in 2 dimensions.
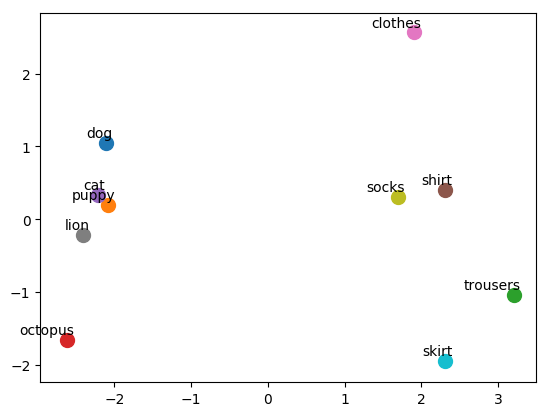
The words that are closer together have a similar meaning or context. Using the distances between word vectors things get interesting. Let’s define a function to do this using the cosine distance between two word vectors and then test it out (back to 50 dimensions!)
cosine(x,y)=1-cosine_dist(x, y)
The following cell shows that the cosine similarity between dog and puppy is larger than the similarity between trousers and octopus, thereby demonstrating that the vectors are working how we expect them to
cosine(vec("dog"), vec("puppy")) > cosine(vec("trousers"),vec("octopus"))
true
Now let’s define a function to give us a list of nearest neighbouring words.
function closest(v, n=20)
list=[(x,cosine(embeddings'[x,:], v)) for x in 1:size(embeddings)[2]]
topn_idx=sort(list, by = x -> x[2], rev=true)[1:n]
return [vocab[a] for (a,_) in topn_idx]
end
Testing this out on the word “wine” we can see that list of words returned are all related words. It’s pretty remarkable given the word relationships were ‘learned’ and not specified by a human thesaurus word boffin.
closest(vec("wine"))
20-element Array{String,1}:
"wine"
"wines"
"tasting"
"coffee"
"beer"
"champagne"
"drink"
"taste"
"grape"
"drinks"
"beers"
"bottled"
"gourmet"
"blend"
"chocolate"
"tastes"
"dessert"
"flavor"
"fruit"
"cooking"
Math on words
Water + Frozen
closest(vec("water") + vec("frozen"))
20-element Array{String,1}:
"water"
"frozen"
"dry"
"dried"
"salt"
"milk"
"oil"
"waste"
"liquid"
"ice"
"freezing"
"covered"
"hot"
"drain"
"food"
"sand"
"sugar"
"soil"
"contaminated"
"cold"
Amazingly the list contains ice!
Halfway between Day and Night
closest(mean([vec("day"), vec("night")]))
20-element Array{String,1}:
"night"
"day"
"days"
"weekend"
"morning"
"sunday"
"afternoon"
"saturday"
"came"
"week"
"evening"
"coming"
"next"
"on"
"before"
"hours"
"weeks"
"went"
"hour"
"time"
The list contains morning and afternoon!
Blue is to Sky as X is to Grass
blue_to_sky = vec("blue") - vec("sky")
closest(blue_to_sky + vec("grass"))
20-element Array{String,1}:
"grass"
"green"
"leaf"
"cane"
"bamboo"
"trees"
"grasses"
"tree"
"yellow"
"lawn"
"cotton"
"lawns"
"red"
"pink"
"farm"
"turf"
"vine"
"rubber"
"soft"
"chestnut"
Green is there at the top!
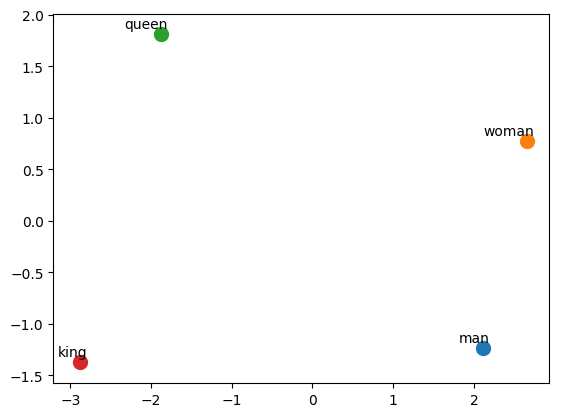
Man - Woman + Queen
closest(vec("man") - vec("woman") + vec("queen"))
20-element Array{String,1}:
"queen"
"king"
"prince"
"crown"
"coronation"
"royal"
"knight"
"lord"
"lady"
"ii"
"great"
"majesty"
"honour"
"name"
"palace"
"crowned"
"famous"
"throne"
"dragon"
"named"
King = Magic!
Sentence Similarity with Dracula
Load the book Dracular by Bram Stoker from this website as plain text - https://www.gutenberg.org/ebooks/345
txt = open("pg345.txt") do file
read(file, String)
end
println("Loaded Dracula, length=$(length(txt)) characters")
Loaded Dracula, length=883114 characters
The next cell tidies up the book’s data by removing characters that are not alpha-numeric and splits the text up into an array of sentences.
txt = replace(txt, r"\n|\r|_|," => " ")
txt = replace(txt, r"[\"*();!]" => "")
sd=StringDocument(txt)
prepare!(sd, strip_whitespace)
sentences = split_sentences(sd.text)
i=1
for s in 1:length(sentences)
if length(split(sentences[s]))>3
sentences[i]=lowercase(replace(sentences[s], "."=>""))
i+=1
end
end
sentences[1000:1010]
Ouput of sentences 1000 to 1010
11-element Array{SubString{String},1}:
"he seems absolutely imperturbable"
"i can fancy what a wonderful power he must have over his patients"
"he has a curious habit of looking one straight in the face as if trying to read one's thoughts"
"he tries this on very much with me but i flatter myself he has got a tough nut to crack"
"i know that from my glass"
"do you ever try to read your own face?"
"i do and i can tell you it is not a bad study and gives you more trouble than you can well fancy if you have never tried it"
"he says that i afford him a curious psychological study and i humbly think i do"
"i do not as you know take sufficient interest in dress to be able to describe the new fashions"
"dress is a bore"
"that is slang again but never mind arthur says that every day"
This next function sentvec takes the vectors of each word in the array and finds the mean vector of the whole sentence.
function sentvec(s)
local arr=[]
for w in split(sentences[s])
if vec(w)!=nothing
push!(arr, vec(w))
end
end
if length(arr)==0
ones(Float32, (50,1))*999
else
mean(arr)
end
end
sentences[101]
"there was everywhere a bewildering mass of fruit blossom--apple plum pear cherry and as we drove by i could see the green grass under the trees spangled with the fallen petals"
sentvec(100)
50-element Array{Float32,1}:
0.3447293
0.39965677
-0.054723457
-0.07291292
0.21394199
0.15642972
-0.49596983
-0.24674776
-0.23787305
-0.4288543
-0.314565
-0.18126178
-0.15339927
⋮
0.08461739
-0.20704514
-0.22955278
-0.011368492
0.03529108
0.057512715
-0.0074529666
0.02252327
0.037329756
-0.52179056
-0.076994695
-0.49725753
This function returns the n nearest sentences (without any pretraining).
function closest_sent(input_str, n=20)
mean_vec_input=mean([vec(w) for w in split(input_str)])
list=[(x,cosine(mean_vec_input, sentvec(x))) for x in 1:length(sentences)]
topn_idx=sort(list, by = x -> x[2], rev=true)[1:n]
return [sentences[a] for (a,_) in topn_idx]
end
closest_sent("my favorite food is strawberry ice cream")
20-element Array{String,1}:
"we get hot soup or coffee or tea and off we go"
"there is not even a toilet glass on my table and i had to get the little shaving glass from my bag before i could either shave or brush my hair"
"i had for dinner or rather supper a chicken done up some way with red pepper which was very good but thirsty"
"drink it off like a good child"
"no you don't you couldn't with eyebrows like yours"
"oh yes they like the lotus flower make your trouble forgotten"
"this with some cheese and a salad and a bottle of old tokay of which i had two glasses was my supper"
"but lor' love yer 'art now that the old 'ooman has stuck a chunk of her tea-cake in me an' rinsed me out with her bloomin' old teapot and i've lit hup you may scratch my ears for all you're worth and won't git even a growl out of me"
"i know that from my glass"
"i found my dear one oh so thin and pale and weak-looking"
"And I like it not."
"she has more colour in her cheeks than usual and looks oh so sweet"
"i can go with you now if you like"
"make them get heat and fire and a warm bath"
"i felt in my heart a wicked burning desire that they would kiss me with those red lips"
"give me some water my lips are dry and i shall try to tell you"
"oh what a strange meeting and how it all makes my head whirl round i feel like one in a dream"
"so i said:-- you like life and you want life?"
"i had for breakfast more paprika and a sort of porridge of maize flour which they said was mamaliga and egg-plant stuffed with forcemeat a very excellent dish which they call impletata"
"for a little bit her breast heaved softly and her breath came and went like a tired child's"
It’s interesting to see the sentences returned - they are indeed mostly similar.
As the sentence similarity function is slow to run I created a pre-trained array of all the sentences and the corresponding word vectors.
drac_sent_vecs=[]
for s in 1:length(sentences)
i==1 ? drac_sent_vecs=sentvec(s) : push!(drac_sent_vecs,sentvec(s))
end
Save data to files (to save doing the training step next time).
writedlm( "drac_sent_vec.csv", drac_sent_vecs, ',')
writedlm( "drac_sentences.csv", sentences, ',')
Open the files
sentences=readdlm("drac_sentences.csv", '!', String, header=false)
drac_sent_vecs=readdlm("drac_sent_vec.csv", ',', Float32, header=false)
8093×50 Array{Float32,2}:
0.395886 0.136462 0.0393325 … -0.00172208 -0.094155
0.105341 0.298508 -0.108769 -0.11237 0.108809
0.306499 0.372668 0.0499599 0.011585 -0.0269931
0.439134 0.237768 -0.157471 -0.047655 -0.206138
0.479465 0.0339237 0.0574679 -0.0110334 -0.0810052
0.305005 0.236101 -0.167058 … -0.161612 -0.481633
0.274253 -0.103281 -0.0939105 -0.0443089 -0.0691436
0.454941 0.308015 -0.376682 0.118407 -0.017146
0.280243 0.0355603 -0.371213 -0.054871 0.0895917
0.303624 0.24452 -0.259576 -0.0073874 0.372042
0.292713 0.0700706 -0.128396 … -0.0598984 0.0768687
0.427364 0.0626689 -0.00844564 -0.0528361 0.20124
0.42247 0.139159 -0.134028 -0.109309 -0.322777
⋮ ⋱
0.527544 0.0679754 -0.0678955 -0.0834867 -0.141069
0.274218 -0.120684 -0.176243 0.156214 -0.2699
0.364304 0.277423 0.163191 0.00988463 -0.119377
0.386379 0.203583 0.148782 -6.83427e-5 -0.125681
0.0938667 0.214723 0.586457 … -0.0834033 0.454743
-0.66594 -0.6551 0.92148 -0.42447 -0.058735
0.447467 0.25429 -0.151193 -0.0932182 -0.244452
0.215579 0.135113 0.0431876 -0.307311 -0.121217
0.374962 0.121228 -0.172914 -0.106937 -0.301211
0.194821 -0.0167174 -0.0303678 … 0.0276704 0.168872
0.605342 0.221943 0.21447 -0.143455 0.00104976
999.0 999.0 999.0 999.0 999.0
Redefine the sentence similarity function to look at the pre-trained array.
function closest_sent_pretrained(pretrained_arr, input_str, n=20)
mean_vec_input=mean([vec(w) for w in split(input_str)])
list=[(x,cosine(mean_vec_input, pretrained_arr[x,:])) for x in 1:length(sentences)]
topn_idx=sort(list, by = x -> x[2], rev=true)[1:n]
return [sentences[a] for (a,_) in topn_idx]
end
Test it out and the results are instant this time.
closest_sent_pretrained(drac_sent_vecs, "i walked into a door")
20-element Array{String,1}:
"with a glad heart i opened my door and ran down to the hall"
"i held my door open as he went away and watched him go into his room and close the door"
"again a shock: my door was fastened on the outside"
"suddenly he called out:-- look madam mina look look i sprang up and stood beside him on the rock he handed me his glasses and pointed"
"then lucy took me upstairs and showed me a room next her own where a cozy fire was burning"
"i keep the key of our door always fastened to my wrist at night but she gets up and walks about the room and sits at the open window"
"just before twelve o'clock i just took a look round afore turnin' in an' bust me but when i kem opposite to old bersicker's cage i see the rails broken and twisted about and the cage empty"
"if he go through a doorway he must open the door like a mortal"
"i went to the door"
"when i came back i found him walking hurriedly up and down the room his face all ablaze with excitement"
"i came back to my room and threw myself on my knees"
"after a few minutes' staring at nothing jonathan's eyes closed and he went quietly into a sleep with his head on my shoulder"
"every window and door was fastened and locked and i returned baffled to the porch"
"i sat down beside him and took his hand"
"bah with a contemptuous sneer he passed quickly through the door and we heard the rusty bolt creak as he fastened it behind him"
"passing through this he opened another door and motioned me to enter"
"Suddenly he called out:-- Look Madam Mina look look I sprang up and stood beside him on the rock he handed me his glasses and pointed."
"just outside stretched on a mattress lay mr morris wide awake"
"i could see easily for we did not leave the room in darkness she had placed a warning hand over my mouth and now she whispered in my ear:-- hush there is someone in the corridor i got up softly and crossing the room gently opened the door"
"i have to be away till the afternoon so sleep well and dream well with a courteous bow he opened for me himself the door to the octagonal room and i entered my bedroom"
Leave a comment